
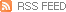
‘Triple V ’로 보는 빅데이터
- 거대함, 다양함, 빠른속도(Volume, Variety, Velocity)

위의 자료는 다음(Daum)사에서 제공하는 SNS 빅데이터 사이트인 ‘소셜 매트릭스’에서 ‘의대’라는 키워드로 검색한 결과이다. 검색결과는 한 달간 트위터와 블로그에서 작성된 ‘의대’라는 키워드에 대한 심리적 연관어의 순위를 매겨 그래프와 도표로 나타내었다. 연관 검색어를 자세히 보면 불합격(325건)>합격(215건)>빨갱이(138건)>끝내주다(136건)>충실하다(136건)등으로 나타났다. 또한 하루 단위로 보았을 때 사용 빈도나‘의대생’에 대한 생각이 긍정적인지 부정적인지 알 수 있었다.
이렇듯 최근 빅데이터(big-data)라는 용어가 경제, 경영분야를 중심으로 다양한 분야에서 사용 되고 있다. 빅데이터라는 말이 유행하기 전에 이미 고객 데이터 추적과 수집 등 고객관리 일환으로 발생한 문자 그대로의 큰(big) 정보(data)를 지칭하는 일반 명사적 의미로 ‘big data(큰 정보)’를 사용하였다. 하지만 2011년도 세계적인 컨설팅업체 맥킨지(Mckinsey)보고서에서 저장만 하고 방치된 정보데이터나 그 기록들중 미래의 활용 가능성이 높은 것으로 정의한 후 고유명사 격으로 자리 잡고 큰 유행이 되었다. IT기기의 발전과 함께 무한정 생산되는 데이터를 적극 분석하기 위해 정의의 범위가 확장 된 것이다. 이러한 빅데이터를 흔히 거대한 크기(Volume), 다양한 형태(Variety), 빠른 이용 속도(Velocity)의 3가지 요소를 들어가며 설명한다. 이 3가지 요소를 각각 소개하고 이를 바탕으로 빅데이터의 응용 사례를 소개한다.
Volume(거대함) : 사소한 데이터도 저장, 표본 분석을 넘어서 전수데이터 분석이 가능
한국전자통신연구원(KETRI) 자료에 의하면 최근 컴퓨터, 인터넷, 스마트폰과 SNS의 발달로 데이터 생산을 가속하여 전 세계에서 2011년 한해에만 미국 의회도서관 저장 정보량의 400만배에 해당하는 1조8GB(기가바이트)를 생산하는 등 데이터가 폭증하고 있는 것으로 나타났다. 규모 뿐 아니라 이를 뒷받침하는 데이터 입출력 기법의 발달과 데이터 저장 가격의 하락도 대형화에 영향을 주고 있다. 삼성경제연구소(SERI)에서 2010년 추산한 단위 저장량 당 하드디스크의 가격은 2000년의 1/80의 수준으로 떨어진 것을 알 수 있다. 따라서 그동안 저장 가치가 없어서 버렸던 매우 많은 양의 데이터가 본격적으로 축적되기 시작하였다. 그리고 저장 장치 규모의 증가로 인해 통계가 표본추출의 개념에서 전수분석이 가능하게 돼서 정보의 왜곡도 적어지는 효과도 나타났다. 이로 인해 최근 빅데이터에서 전수분석을 할 수 있는 새로운 데이터 분석 기법이 활발하게 개발되고 있다.
Variety(다양함) : SNS, 댓글, 사진, 전화통화 그리고 동영상까지도 분석 대상
시장 조사 업체인 IDC(Internati-onal Data Corporation)조사에 따르면 각 데이터가 크기와 형태가 다르기 때문에 기존의 방식으로 처리하기 어려운 경우가 90%이상인 것으로 나타났다. 즉, 설문조사, 각종 회계자료와 매출정보는 지금까지 많이 사용된 데이터의 종류지만 SNS 글과 댓글, 사진, 전화통화량, 전화 시간 데이터 그리고 동영상 등은 정의되거나 해석을 위해 축적된 데이터는 아니다. 따라서 이러한 형식의 데이터들은 전통적인 프로그래밍 방식으로 이해되기 어려워서 지금까지 축적하지 않거나 분석을 하지 않았다. 일례로 미국의 한 통신사는 매일 170억건의 휴대전화 통화 및 송수신 내역을 담은 데이터의 시간의 속성을 이용해 정보를 가공 한 후 교통 정책 분야에 적용시켰다. 서울시 교통정책과는 2013년 KT의 통화량 데이터와 서울시의 교통 데이터를 이용해 심야버스노선을 개선했다. 특히 통화량 데이터로 홍대, 동대문, 신림, 강남, 종로 순으로 유동인구가 많다는 것을 파악하고, 교통데이터로 심야택시 승하차 데이터를 분석해 유동인구를 위치 정보로 시각화하여 심야버스 노선을 만들어 운행하고 있다. 다른 예로 모바일 앱인 ‘텍스트앳’은 예전에는 특별한 데이터로 생각하지 않았던 10만명, 5억 개 이상의 카카오톡의 실제 내용을 바탕으로 자주 쓰는 말투나 단어를 바탕으로 메신저 상의 상대의 감정을 분석해 준다. 또한 상대방의 현재 감정 상태와 일별, 월별에 따른 감정 추이도 함께 보여준다.
Velocity(빠른속도) : 정보의 빠른 확산, 전파 속도 분석 그리고 정보의 생중계가 가능
미국의 대표적인 블로그 뉴스인 허핑턴 포스트(The Huffington Post)에서 각 표준시간대별 2013년 새해 시작 직후 1초 당 트윗이 가장 많이 나온 나라로 1초당 트윗이 33,388개였던 대한민국과 일본을 꼽았다. 이렇듯 데이터 처리 속도가 분, 초 단위 이하로 단축되어서 특정 사건 발생과 SNS의 글 발생 속도를 연관시켜 분석해보면 사건이 얼마나 빠르게 확산되는지도 알 수 있다. 또한 데이터 입력, 처리속도가 실시간으로 가능해 지면서 데이터의 생중계(nowcasting)가 가능하게 되었다.
이러한 빅데이터가 의학 분야에는 어떻게 적용 될 수 있을까? 예전에는 질병의 역학적 연구에서는 정부에서 제공하는 질병의 통계로 해당 질병의 전파 등을 예측해 왔다. 하지만 최근 이 틀을 깨고 구글(Google)의 독감 트렌드는 구글에서 매 주 단위로 독감과 관련된 검색어 수를 익명으로 수집하여 전 세계 국가 및 지역에서 독감이 얼마나 유행하는지를 알 수 있고 더 나아가 예측할 수 있는 시스템을 만들었다. 구글 독감 트렌드에서 예상 수치와 기존의 독감 유행 수준 지표는 유사함이 입증되어 2009년도 네이쳐(Nature)지에 실리기도 하였다. 이를 바탕으로 다른 질병에 대한 역학적 트렌드를 제시하는 노력이 시도되고 있다.
문선재 기자/중앙
<mgstoner@naver.com>
'97호 > 의료사회' 카테고리의 다른 글
| CT 환자 방사선 피폭량 (0) | 2015.05.15 |
|---|---|
| Biodigital사의 수술시뮬레이션 (0) | 2015.05.15 |
| 조류인플루엔자 파헤치기 (0) | 2015.05.15 |



